Week 05 Tutorial Questions
Hashing, Heaps, and Tries
Hashing
Resources
-
Consider this potential hash function:
int hash(char *key, int N) { int h = 0; char *c; for (c = key; *c != '\0'; c++) { h = h + *c; } return h % N; }
How does this function convert strings to
ints?What are the deficiencies with this function and how can it be improved?
-
For a hash table of size \( N \) that uses separate chaining for collision resolution, with the chains sorted in ascending order on key value, what are the best case and worst case costs for inserting \( k = 2N \) items into the table? Assume that insertion cost is measured in terms of number of key comparisons. What will be average search cost after all the insertions are done?
-
Consider a very small hash table with only 11 entries, and a simple hash function \( h(x) = x\ \%\ 11 \). If we start with an empty table and insert the following values in the order shown
11 16 27 35 22 20 15 24 29 19 13
give the final state of the table for each of the following collision resolution strategies
- separate chaining, with chains in ascending order
- linear probing
- double hashing, with \( h_2(x) = (x\ \%\ 3) + 1 \)
-
Both hash tables and balanced search trees (e.g., AVL trees and 2-3-4 trees) are efficient data structures that can be used for the insertion, searching and deletion of key-value pairs. Compare the advantages and disadvantages of each.
-
In lectures, we discussed how to solve the famous two-sum problem efficiently using a hash table. Taking inspiration from that, let's see if you can now solve the three-sum problem!
Here's the problem - given an array of integers and a target sum \(S\), determine whether the array contains three integers that sum to \(S\). Try to find a solution that is \(O(n^2)\) on average.
bool threeSum(int arr[], int size, int sum);
As a reminder, here are the hash table operations:
HashTable HashTableNew(void); void HashTableFree(HashTable ht); void HashTableInsert(HashTable ht, int key, int value); bool HashTableContains(HashTable ht, int key); int HashTableGet(HashTable ht, int key); void HashTableDelete(HashTable ht, int key); int HashTableSize(HashTable ht);
-
Fun fact: 2521 is a prime number! If a hash table which stores integer keys had 2521 slots and used double hashing for collision resolution, define a suitable secondary hash function \(h_2\) for the table. Briefly comment on what makes it suitable.
-
Calls to functions (e.g. some recursive functions) are sometimes very expensive to compute. One often-employed trick when working with such functions is memoisation: the first time the function is called with some input, we cache this result (i.e. store it somewhere for use later on), and then for subsequent calls to the function with the same input, we consult the cache rather than actually evaluating the call.
- Design an ADT for a memoiser that supports memoisation of an expensive single-argument function.
- One potential problem with memoisation is that the cache's memory usage can grow quite large when the function is called for lots of inputs. This is often solved by limiting the size of the cache and having a policy which can be used to pick entries to remove from the cache to make more room. What are some possible policies you could use?
- Can you think of how you would actually implement some of these policies?
Heaps
-
Using the heap-as-array data structure from lectures, show how an initially empty max heap changes when the following values are inserted.
S O R T I N G I S F U N
At each step, show how the
fixUp()function is used. -
Consider the series of heap operations below. Assuming that higher values have higher priority, show the state of the heap (in both binary tree form and array form) after each operation.
Heap h; Item it; h = heapNew(); heapInsert(h, 10); heapInsert(h, 5); heapInsert(h, 15); heapInsert(h , 3); heapInsert(h, 16); heapInsert(h, 13); heapInsert(h, 6); it = heapDelete(h); heapInsert(h, 2); it = heapDelete(h); it = heapDelete(h); it = heapDelete(h); it = heapDelete(h); it = heapDelete(h);
Tries
Resources
-
Consider the following trie:
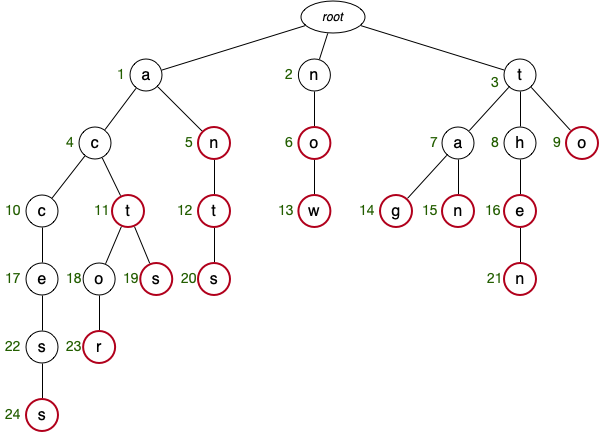
Show which nodes would be visited when searching for each of the following words:
nowtheantaccessactoractionactorstanga
-
Under what circumstances would inserting a new word into a trie not result in adding any new nodes? What would be the effect on the tree of inserting the word?
-
Show the final trie resulting from inserting the following words into an initially empty trie.
so boo jaws boon boot axe jaw boots sore
Does the order that the words are inserted affect the shape of the tree?
-
What are the two cases when deleting a word from a trie? How is each case handled?
-
Autocomplete is a feature in which an application predicts the rest of a word a user is typing. For example, if a user has typed in "th", then autocomplete may suggest the words "the", "they", "then", and so on.
- Explain how a trie could be used to implement basic autocomplete, which suggests all possible words.
- Users are much more likely to type some words than others, so ideally autocomplete should suggest more likely words. For example, if a user has typed "tho", autocomplete should suggest "though" instead of "thou". How could you extend your solution so that autocomplete suggests more likely words?