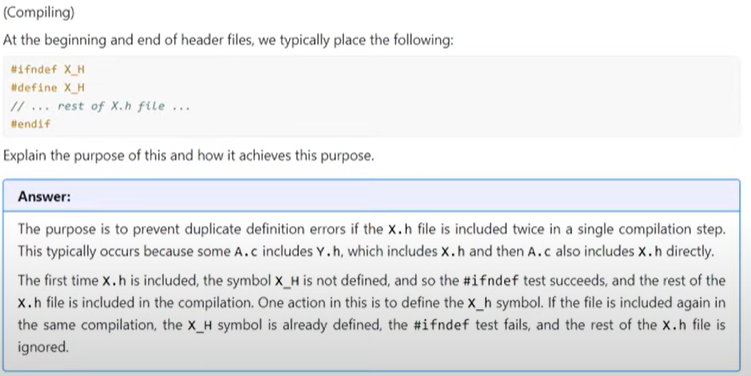
Malloc requires the stdlib.h header file to function.
Note: malloc does not intialise the memory it allocates. If you want to initialise the memory to a specific value, you can use calloc, which works similar to malloc but sets all bytes of the allocated memory to zero.Here are a few examples on malloc memory allocation:
// Allocate memory for an int
int* ptr = (int*)malloc(sizeof(int));
int* ptr = malloc(sizeof(int));
// Allocate memory for a char
char* ptr = (char*)malloc(sizeof(char));
char* ptr = malloc(sizeof(char));
// Allocate memory for a string with a maximum of 100 characters (including the null terminator)
char* ptr = (char*)malloc(100 * sizeof(char));
char* ptr = malloc(100 * sizeof(char));
// Allocate memory for a struct
struct node {
int value;
struct node *next;
};
struct node* newNode = (struct node*)malloc(sizeof(struct node));
struct node* newNode = malloc(sizeof(struct node));
// Allocate memory for an array of 5 integers
int* ptr = (int*)malloc(5 * sizeof(int));
int* ptr = malloc(5 * sizeof(int));
When using malloc, make sure to check whether the memory allocation is successful.
ptr = (int*)malloc(size * sizeof(int));
if (ptr == NULL) {
// Print an error message to the standard error stream (stderr)
fprintf(stderr, "Memory allocation failed. Exiting the program.\n");
// Exit the program with an error code
exit(1);
}
Lastly, don't forget to free the memory using 'free' when you are done using the variable(s) to avoid memory leaks.
free(ptr);