A very important part of the course. Understanding the time and storage demands of different data structures and algorithms is critical in writing the right code for a program.
Real: physical time it took. (Quite close to the sum of user and sys.
User: the time it takes for your program to run.
Sys: things that the OS is doing (think: opening a file, making a network request, mallocing memory, etc.)
- Small / fast programs are hard to determine the time for. They are deceiving. Larger programs give us a more realistic measurement of their efficiency.
- The example programs discussed in the lectures use a constant amount of memory regardless of the increasing time taken to compute their equally increasing input sizes.
There is no syntax for pseudocode - a middle step between understanding and coding a problem up.
Theoretical Performance Analysis looks at pseudocode to evaluate the complexity of a program regardless of the hardware or software environment. This time complexity is expressed as an equation based on a variable ‘n’ where ‘n’ is the number of input elements.
Space Complexity (will be looked at later in the course): How much memory does this program use? How many bytes does it need to actually run?
- It doesn’t depend on n.
‘Constant time’: When your algorithm is not dependent on the input size n, it is said to have a constant time complexity. This means that the run time will always be the same regardless of the input size.
- log*n grows slower than any kind of n
<u>Time complexity describes how an algorithm scales (in terms of the amount of time taken) as the input size increases. Knowing the time complexity alone is not sufficient to determine how long an algorithm will take for a single given input size.</u>
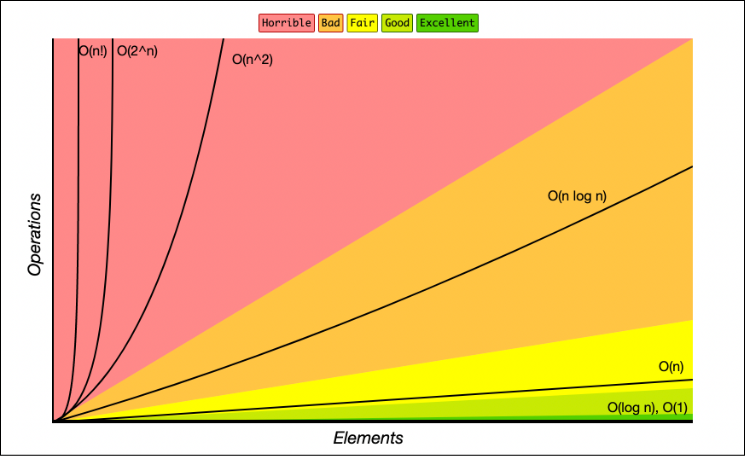
Algoirthm Analysis:
Useful for looking at how programs scale, not necessarily how fast it runs.
Complexity is talking about asymptotic behaviour (we are describing the limiting behaviour).
- The Upper Bound (O) of an algorithm's complexity describes how the algorithm's execution time changes with a change in the amount of data being processed in the operation, meaning that a more complex algorithm will often take an increasingly (often not linearly) long time to execute as the amount of data is increased.
- Asymptotes come into effect only when the input is large enough - this is when scale is considered. Complexity does not deal with small numbers, as they are unreliable and computers don’t deal with them as well as it does with big numbers.
Time complexity essentially asks for the tightest bound you can get ⇒ How quickly does your program run in the worst case?

