1

Double Hashing Example
A = 65 % 5 = 0
F = 70 % 5 = 0
B = 66 % 5 = 1
C = 67 % 5 = 2
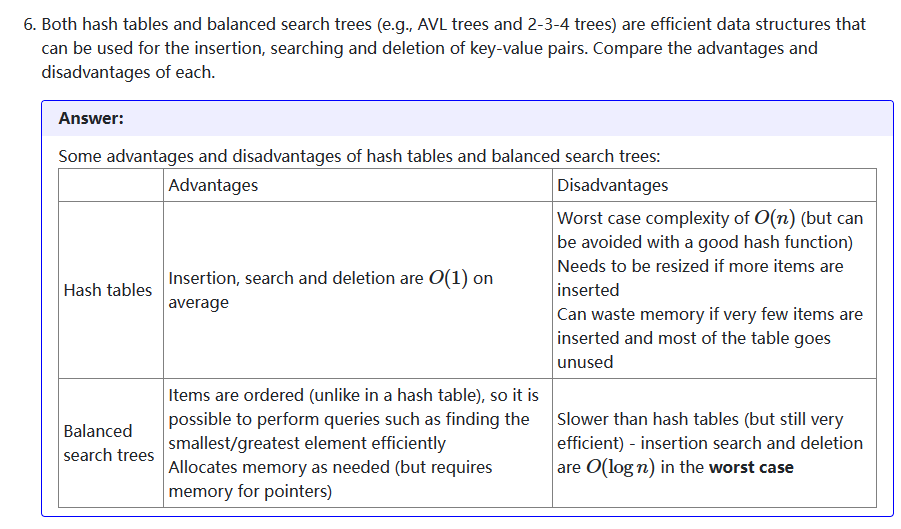
linear probing
| [0] | [1] | [2] | [3] | [4] |
| A | F | B | C |
double hashing
A and F collision
when h2(x) = 1 + h1(x)/m % (m-1) where m is length of hash table
F will be 1 + 70 / 5 % 4 = 1 + 2 = 3
| [0] | [1] | [2] | [3] | [4] |
| A | B | F |
Hashing function structure
value is "convert key to 32-but int"
and returning the value modulo of N, we will get hashed number
Convert string to int
when given parameter is pointer of char (string)
int res = 0
start for loop i < string length of given string
add string[i] to res
end for loop
return res
1
given the hash function is (int N % 10)
Since we are inserting all the numbers from 1 to N, the items will be
uniformly distributed across all the indexes. Thus the longest chain
length will be ceil(N / 10) . Hence the worst-case search cost in terms
of the number of items examined is ceil(N / 10).
#include "HashMap.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void insert_handler(unordered_map hashmap, int key_hv, struct Value *insert);
// Your TODOS
int string_to_int(char *str) {
int res = 0;
for (int i = 0; i < strlen(str); ++i) {
res += str[i];
}
return res;
};
// Really basic modulo hashing function:
// Takes in a string called str, and m should be a prime
// number representing bucket_count
int hash(char *str, int m) { return string_to_int(str) % m; }
unordered_map HashMap_new(int n) {
unordered_map new = malloc(sizeof(struct HashMap));
int pn = next_prime(n);
new->bucket_count = pn;
new->buckets = malloc(pn * sizeof(struct Value));
// Initialise our malloced array
for (int i = 0; i < pn; ++i) {
new->buckets[i] = NULL;
}
return new;
};
void HashMap_insert(unordered_map hashmap, char *key, char *value) {
struct Value *new = malloc(sizeof(struct Value));
new->key = key;
new->value = value;
new->next = NULL;
int key_hv = hash(key, hashmap->bucket_count);
insert_handler(hashmap, key_hv, new);
};
void insert_handler(unordered_map hashmap, int key_hv, struct Value *insert) {
if (hashmap->buckets[key_hv] == NULL) {
hashmap->buckets[key_hv] = insert;
return;
}
struct Value *curr = hashmap->buckets[key_hv];
if (strcmp(curr->key, insert->key) == 0) {
free(curr->value);
curr->value = insert->value;
free(insert->key);
free(insert);
return;
}
while (curr->next != NULL) {
if (strcmp(curr->next->key, insert->key) == 0) {
free(curr->next->value);
curr->next->value = insert->value;
free(insert->key);
free(insert);
return;
}
curr = curr->next;
}
curr->next = insert;
}
char *HashMap_get(unordered_map hashmap, char *key) {
int key_hv = hash(key, hashmap->bucket_count);
struct Value *curr = hashmap->buckets[key_hv];
while (curr != NULL && strcmp(curr->key, key) != 0) {
curr = curr->next;
}
return (curr == NULL) ? "Not Found" : curr->value;
};
/**
* Given Functions, (Try not to change these)
*/
bool is_prime(int n) {
if (n <= 1)
return false;
if (n <= 3)
return true;
if (n % 2 == 0 || n % 3 == 0)
return false;
for (int i = 5; i * i < n; i += 6) {
if (n % i == 0 || n % (i + 2) == 0)
return false;
}
return true;
}
int next_prime(int n) {
if (n <= 2)
return 2;
while (!is_prime(n)) {
n++;
}
return n;
}
void HashMap_print(unordered_map hashmap) {
for (int i = 0; i < hashmap->bucket_count; ++i) {
struct Value *curr = hashmap->buckets[i];
int f = 0;
printf("%d: ", i);
while (curr != NULL) {
if (f != 0) {
printf("->%s %s", curr->key, curr->value);
} else {
printf("%s %s", curr->key, curr->value);
}
curr = curr->next;
f++;
}
printf("\n");
}
}
void HashMap_free(unordered_map hashmap) {
for (int i = 0; i < hashmap->bucket_count; ++i) {
struct Value *curr = hashmap->buckets[i];
if (curr == NULL) {
free(hashmap->buckets[i]);
continue;
}
while (curr != NULL) {
struct Value *temp = curr->next;
free(curr->value);
free(curr->key);
free(curr);
curr = temp;
}
}
free(hashmap->buckets);
free(hashmap);
}
Ways to resolve hash collisions include:
advantages
disadvantages
Hash functions take a given key and output an integer from 0 to N - 1. The basic mechanism of a hash function is shown below.
int hash(Key key, int N) {
int val = convert key to 32-bit int;
return val % N;
}