Assignment 2
Simple Search Engines
Changelog
All changes to the assignment specification and files will be listed here.
[02/11 10:00]Assignment released[02/11 22:00]Added additional clarifications and assumptions[07/11 16:20]Updated theMakefileby adding the-foption torm. Download the new version here. Also added information about testing.
Admin
- Marks
- contributes 20% towards your final mark (see Assessment section for more details)
- Submit
- see the Submission section
- Deadline
- 8pm on Friday of Week 10
- Late penalty
- 1% off the maximum mark for each hour late. For example if an assignment worth 80% was submitted 15 hours late, the late penalty would have no effect. If the same assignment was submitted 24 hours late it would be awarded 76%, the maximum mark it can achieve at that time.
Background
In this assignment, your task is to implement a simple search engine using a simplified version of the well-known Weighted PageRank algorithm. You should start by reading the Wikipedia article on PageRank (read up to the section Damping Factor). Later I will release a video lecture introducing this assignment and discuss the required topics.
The main focus of this assignment is to build a graph structure from a set of web pages, calculate Weighted PageRanks and rank pages. To make things easier for you, you don't need to spend time crawling, collecting and parsing web pages for this assignment. Instead, you will be provided with a collection of mock web pages in the form of plain text files. Each web page has two sections:
- Section 1 contains URLs representing outgoing links. The URLs are separated by whitespace, and may be spread across multiple lines.
- Section 2 contains the actual content of the web page, and consists of one or more words. Words are separated by whitespace, and may be spread across multiple lines.
Here is an example web page:
#start Section-1 url2 url34 url1 url26 url52 url21 url74 url6 url82 #end Section-1 #start Section-2 Mars has long been the subject of human interest. Early telescopic observations revealed color changes on the surface that were attributed to seasonal vegetation and apparent linear features were ascribed to intelligent design. #end Section-2
Sections will always be appropriately delimited by lines containing #start Section-1, #end Section-1, #start Section-2 and #end Section-2. There will be no other characters on these lines (no leading or trailing whitespace). There may be lines containing whitespace before or after any section. Web pages contain exactly one of each section, and Section 1 will always precede Section 2.
Note that it is completely valid for Section 1 to be empty - this simply means that the web page does not have any outgoing links.
Setting Up
Change into the directory you created for the assignment and run the following command:
unzip /web/cs2521/21T3/ass/ass2/downloads/files.zip
If you're working at home, download files.zip by clicking on the above link and then run the unzip command on the downloaded file.
If you've done the above correctly, you should now have the following files:
Makefile- a set of dependencies used to control compilation
pagerank.c- a stub file for Part 1
searchPagerank.c- a stub file for Part 2
scaledFootrule.c- a stub file for Part 3
ex1,ex2andex3- directories containing test files
Each test directory contains the following files:
collection.txt- a file that contains a list of relevant URLs (for Part 1)
pagerankList.exp- a file that contains the expected result of Part 1 for this collection of URLs
invertedIndex.txt- a file containing the inverted index for this collection of URLs (for Part 2)
log.txt- a file that contains information that may be useful for debugging Part 1
First, compile the original version of the files using the make command. You'll see that it produces three executables: pagerank, searchPagerank and scaledFootrule. It also copies these executables to the ex1, ex2 and ex3 directories, because when you test your program, you will need to change into one of these directories first.
Note that in this assignment, you are permitted to create as many supporting files as you like. This allows you to compartmentalise your solution into different files. For example, you could implement a Graph ADT in Graph.c and Graph.h. To ensure that these files are actually included in the compilation, you will need to edit the Makefile to include these supporting files; the provided Makefile contains instructions on how to do this.
Part 1 - Weighted PageRanks
Your task is to implement a program in a file called pagerank.c that calculates Weighted PageRanks for a collection of pages.
The URLs of the pages in the collection are given in the file collection.txt. The URLs in collection.txt are separated by whitespace, and may be spread across multiple lines. Here is an example collection.txt:
url25 url31 url2 url102 url78 url32 url98 url33
To get the name of the file that contains the page associated with some URL, simply append .txt to the URL. For example, the page associated with the URL url24 is contained in url24.txt.
For each URL in the collection file, you need to read its corresponding page and build a graph structure using a graph representation of your choice. Then, you must use the algorithm below to calculate the Weighted PageRank for each page.
The simplified Weighted PageRank algorithm you need to implement is shown below. Please note that the formula to calculate PageRank values is slightly different to the one provided in the above paper.
- Read web pages from the collection in file
collection.txtand build a graph structure using a graph representation of your choice - \( N \) = number of URLs in the collection
- For each URL \( p_i \) in the collection
- \( PR(p_i, 0) = \frac{1}{N} \)
- \( iteration = 0 \)
- \( diff = diffPR \)
- While \( iteration < maxIterations \) and \( diff ≥ diffPR \)
- \( t = iteration \)
- For each URL \( p_i \) in the collection $$ PR(p_i, t + 1) = \frac{1 - d}{N} + d \ast \sum_{p_j \in M(p_i)} PR(p_j, t) \ast W_{(p_j, p_i)}^{in} \ast W_{(p_j, p_i)}^{out} $$
-
$$ diff = \sum_{i = 1}^{N} |PR(p_i, t + 1) - PR(p_i, t)| $$
- \( iteration \)++
In the above algorithm:
- \( M(p_i) \) is a set of pages with outgoing links to \( p_i \) (ignore self-loops and parallel edges)
- \( W_{(p_j, p_i)}^{in} \) and \( W_{(p_j, p_i)}^{out} \) are defined in the paper above (see the link "Weighted PageRank")
- \( t \) and \( t + 1 \) correspond to iteration numbers. For example, \( PR(p_i, 2) \) means "the PageRank of \( p_i \) after iteration 2".
Note: When calculating \( W_{(p_j, p_i)}^{out} \), if a page \( k \) has zero outdegree (zero outlinks), \( O_k \) should be 0.5, not zero. This will avoid issues related to division by zero.
Your program in pagerank.c must take three command-line arguments: d (damping factor), diffPR (sum of PageRank differences), maxIterations (maximum number of iterations), and using the algorithm described in this section, calculate the Weighted PageRank for every web page in the collection.
Here is an example of how the program is run:
./pagerank 0.85 0.00001 1000
Each of the expected output files in the provided files were generated using the above command.
Your program should output a list of URLs, one per line, to a file named pagerankList.txt, along with some information about each URL. Each line should begin with a URL, followed by its outdegree and Weighted PageRank (using the format string "%.7lf"). The values should be comma-separated, with a space after each comma. Lines should be sorted in descending order of Weighted PageRank. URLs with the same Weighted PageRank should be ordered alphabetically (ascending) by the URL.
Here is an example pagerankList.txt. Note that this was not generated from any of the provided test files, this is just an example to demonstrate the output format.
url31, 3, 0.0724132 url21, 1, 0.0501995 url11, 3, 0.0449056 url22, 4, 0.0360005 url34, 1, 0.0276197 url23, 3, 0.0234734 url32, 1, 0.0232762
We will use a tolerance of \( 10^{-4} \) to check PageRank values when automarking. This means your answer for a PageRank value will be accepted if it is within \( 10^{-4} \) of the expected value.
Assumptions/Constraints
- All URLs in
collection.txtare distinct. - URLs consist of alphanumeric characters only, and are at most 100 characters in length.
- URLs do not necessarily start with
url. - Web pages may have links to themselves and multiple links to the same web page. You must completely ignore self links and duplicate links, including when calculating the outdegree of each page.
- There will be no missing web pages. This means each URL referenced in
collection.txtor as an outlink in a web page will have a text file associated with it that is appropriately named. Also, every URL referenced as an outlink in a web page will be listed incollection.txt. - The provided command-line arguments will be valid. This means \( d \) will be a double between 0 and 1, \( diffPR \) will be a double greater than 0, and \( maxIterations \) will be a positive integer.
- When we say "ordered alphabetically", we mean as determined by
strcmp, which will compare the ASCII values of the characters. - All the text files required by the program will be in the current working directory when the program is executed. For Part 1, this includes the
collection.txtand all the files containing the web pages.
Part 2 - Simple Search Engine
Your task is to implement a simple search engine in a file called searchPagerank.c that takes one or more search terms and outputs relevant URLs.
The program must make use of the data available in two files: invertedIndex.txt and pagerankList.txt. All other text files are not relevant for this task.
invertedIndex.txt contains data about what pages contain what words. Each line of the file contains one word followed by an alphabetically ordered list of URLs of pages that contain that word. Lines are ordered alphabetically by the initial word. Here is an example invertedIndex.txt:
design url2 url25 url31 mars url101 url25 url31 vegetation url31 url61
pagerankList.txt contains information about web pages including their URL, outdegree and Weighted PageRank. The format of this file is the same as that produced by your pagerank program in Part 1.
The program should take search terms as command-line arguments, find pages with one or more matching search terms and output the top 30 pages in descending order of the number of matching search terms to stdout. Pages with the same number of matching search terms should be ordered in descending order by their Weighted PageRank. Pages with the same number of matching search terms and the same Weighted PageRank should be sorted in increasing lexicographic order by URL.
Here is an example output. Note that this was not necessarily generated from any of the provided test files, this is just an example to demonstrate the output format.
./searchPagerank mars design url31 url25 url2 url101
Assumptions/Constraints
- Relevant assumptions from previous parts apply.
- Search terms will be unique.
- At least one search term will be given to the
searchPagerankprogram. - Search terms will consist entirely of lowercase letters.
- The maximum length of a line in
invertedIndex.txtis 1000 characters. - Words in
invertedIndex.txtwill consist entirely of lowercase letters. - It is not guaranteed that all the search terms will be in
invertedIndex.txt. Search terms that are not ininvertedIndex.txtshould be ignored, since there are no pages that contain them. pagerankList.txtwill contain correct URLs, outdegrees and PageRanks. If you do not produce the correct output in Part 1 then you should copy the expected result frompagerankList.expintopagerankList.txtbefore testing.
Part 3 - Hybrid/Meta Search Engine using Rank Aggregation
Your task is to implement a program in scaledFootrule.c that combines search results (ranks) from multiple sources using Scaled Footrule Rank Aggregation, described below.
Scaled Footrule Rank Aggregation
Suppose that \( \tau_1 \), \( \tau_2 \), ... , \( \tau_k \) are search results (rankings) obtained using \( k \) different criteria. We want to aggregate these results into a single search result that agrees with the original \( k \) results as much as possible.
A weighted bipartite graph for scaled footrule optimization \((C, P, W)\) is defined as:
- \( C \) is the set of pages to be ranked (say, a union of \( \tau_1 \), \( \tau_2 \), ... , \( \tau_k \))
- \( P \) is the set of positions available (say, \(\{1, 2, 3, 4, 5\}\))
- \( W(c, p) \) is the scaled-footrule distance of a ranking that places page \( c \) at position \( p \), given by
$$ W(c, p) = \sum_{i = 1}^{k} \Bigg |\frac{\tau_i(c)}{|\tau_i|} - \frac{p}{n}\Bigg | $$
where
- \( n \) is the cardinality (size) of \( C \)
- \( |\tau_i| \) is the cardinality (size) of \( \tau_i \)
- \( \tau_i(c) \) is the position of \( c \) in \( \tau_i \)
- \( k \) is the number of rank lists
For example:
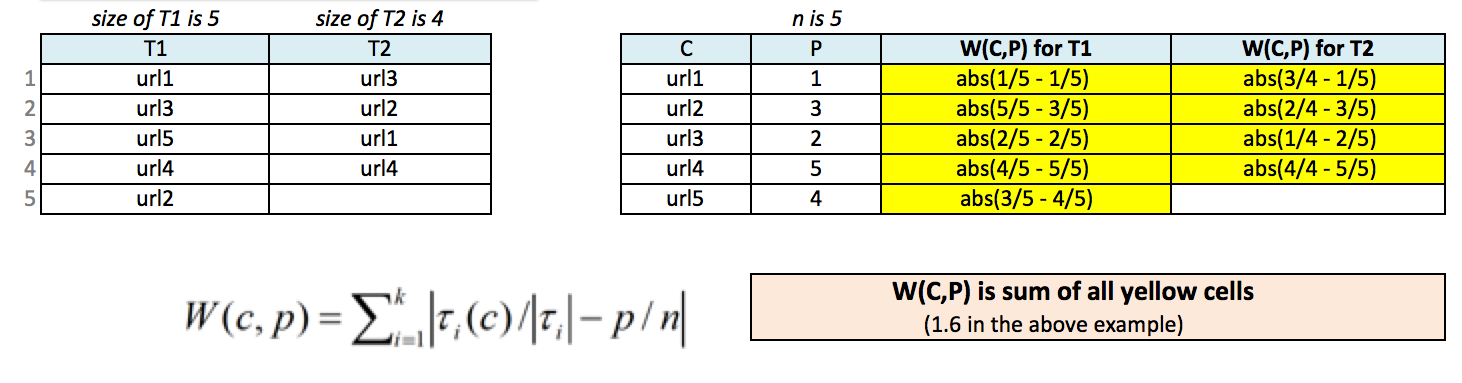
The final ranking is derived by finding possible values of position 'P' such that the total scaled-footrule distance is minimum.
There are many different ways to assign possible values for 'P'. In the above example, P = [1, 3, 2, 5, 4]. Some other possible values are: P = [1, 2, 4, 3, 5], P = [5, 2, 1, 4, 3], P = [1, 2, 3, 4, 5], etc. When n = 5 (i.e., the number of distinct URLs is 5) there are 5! possible alternatives. When n = 10, there are 10! possible alternatives, which is is 3,628,800. A very simple and obviously inefficient approach could use brute-force search and generate all possible alternatives, calculate the total scaled-footrule distance for each alternative, and find the alternative with minimum scaled-footrule distance.
If you use such a brute-force search, you will receive a maximum of 65% for Part 3. However, if you implement a "smart" algorithm that avoids generating unnecessary alternatives, you can receive up to 100% for Part 3. You must document your algorithm such that your tutor can easily understand your logic, and clearly outline how you algorithm reduces the search space, otherwise you will not be awarded marks for your algorithm. Yes, it's only 35% of part-3 marks, but if you try it, you will find it very challenging and rewarding.
Note: You are not permitted to adapt or copy algorithms from the Internet for this task.
You need to write a program in scaledFootrule.c that aggregates ranks from files given as command-line arguments, and outputs an aggregated rank list with the minimum scaled footrule distance.
Example
Suppose that the file rankA.txt contains the following:
url1 url3 url5 url4 url2
And suppose that the file rankB.txt contains the following:
url3 url2 url1 url4
The following command will read ranks from files rankA.txt and rankB.txt and outputs minimum scaled footrule distance (using the format "%.6lf") on the first line, followed by the corresponding aggregated rank list.
./scaledFootrule rankA.txt rankB.txt
Two possible values for P with minimum distance are:
C = [url1, url2, url3, url4, url5] P = [1, 4, 2, 5, 3] P = [1, 5, 2, 4, 3]
Note that there may be multiple values of P that could result in the minimum scaled footrule distance. You only need to output one such list.
P = [1, 4, 2, 5, 3] corresponds to the following list:
1.400000 url1 url3 url5 url2 url4
P = [1, 5, 2, 4, 3] corresponds to the following list:
1.400000 url1 url3 url5 url4 url2
Your program should be able to handle more than two rank files, for example:
./scaledFootrule google.txt bing.txt yahoo.txt myRank.txt
Assumptions/Constraints
- Relevant assumptions from previous parts apply.
- All given rank files will be distinct.
- Each ranking file will contain exactly one URL per line, and no other text. Furthermore, lines do not contain leading or trailing whitespace.
Debugging
Debugging is an important and inevitable aspect of programming. We expect everyone to have an understanding of basic debugging methods, including using print statements, knowing basic GDB commands and running Valgrind. In the forum and in help sessions, tutors will expect you to have made a reasonable attempt to debug your program yourself using these methods before asking for help, and you should be able to explain what you found during your debugging attempts.
You can learn about GDB and Valgrind in the Debugging with GDB and Valgrind lab exercise.
Testing
We have provided some test files for you to test your code for Part 1. Please note that you are expected to develop your own test cases for Parts 2 and 3.
Part 1
Here is an example of how to test Part 1.
# assuming you are currently in your assignment 2 directory make cd ex1 ./pagerank 0.85 0.00001 1000 # your program should have written its output to pagerankList.txt # now compare output in pagerankList.txt with expected output in pageRankList.exp
Note that you can test with other values of \( d \), \( diffPR \) and \( maxIterations \), but you will need to verify the output yourself, as there is no expected output for other values.
Part 2
Here is an example of how to test Part 2.
# assuming you are currently in your assignment 2 directory make cd ex1 ./searchPagerank mars design ... # now verify the output yourself
Obviously, you can test with other search terms and other numbers of search terms, and you will also need to verify the output of this yourself.
Part 3
Here is an example of how to test Part 3.
# assuming you are currently in your assignment 2 directory # assuming that rankA.txt and rankB.txt contain a list of URLs make ./scaledFootrule rankA.txt rankB.txt ... # now verify the output yourself
Note that if you create the rank files in your assignment 2 directory and not in any of the test directories (such as ex1), then you don't need to change into the test directories before running ./scaledFootrule.
You can also test with more rank files, for example:
# assuming you are currently in your assignment 2 directory # assuming that rankA.txt, rankB.txt, rankC.txt and rankD.txt contain a list of URLs make ./scaledFootrule rankA.txt rankB.txt rankC.txt rankD.txt ... # now verify the output yourself
Frequently Asked Questions
- Can we assume X? If the spec does not say you can assume something, then you cannot assume it. However, if you have a reason to think that you should be able to assume something, but the spec does not mention it, then make a post on the forum.
- Are we allowed to use helper functions? Of course. You may implement helper functions in any
.cfile. - Are we allowed to
#includeany additional libraries? No. However, you are allowed to#includeyour own.hfiles. - The specification states that we can assume something. Do we need to check whether this assumption is satisfied? No. If the specification says you can assume something, it means you don't need to check it.
- What errors do we need to handle? No error handling is necessary. However, it is good practice to handle common errors such as: invalid number of command-line arguments, invalid command-line arguments,
NULLreturned fromfopen,NULLreturned frommalloc, even though this is not required in this assignment. - Are we allowed to share tests? No. Testing and coming up with test cases is an important part of software design. Students that test their code more will likely have more correct code, so to ensure fairness, each student should independently develop their own tests.
- What is the point of Section 2 of the web pages? Section 2 is not used in the assignment, since we have already provided
invertedIndex.txt.
Submission
You must submit the three files: pagerank.c, searchPagerank.c and scaledFootrule.c. In addition, you can submit as many supporting files (.c and .h) as you want. Please note that none of your supporting files should contain a main function - only pagerank.c, searchPagerank.c and scaledFootrule.c should contain a main function.
You can submit via the command line using the give command:
give cs2521 ass2 pagerank.c searchPagerank.c scaledFootrule.c your-supporting-files...
or you can submit via WebCMS. You may not submit any other files. You can submit multiple times. Only your last submission will be marked. You can check the files you have submitted here.
Compilation
You must ensure that your final submission compiles on CSE machines. Submitting non-compiling code leads to extra administrative overhead and will result in a 10% penalty.
Here we describe how we will compile your files during autotesting.
To test Part 1, we will rename searchPagerank.c and scaledFootrule.c so they do not end with .c and then compile all the remaining .c files together as follows to produce an executable called pagerank.
mv searchPagerank.c searchPagerank.c~
mv scaledFootrule.c scaledFootrule.c~
gcc -Wall -Werror -g *.c -o pagerank -lm
# run tests
To test Part 2, we will rename pagerank.c and scaledFootrule.c so they do not end with .c and then compile all the remaining .c files together as follows to produce an executable called searchPagerank.
mv pagerank.c pagerank.c~
mv scaledFootrule.c scaledFootrule.c~
gcc -Wall -Werror -g *.c -o searchPagerank -lm
# run tests
To test Part 3, we will rename pagerank.c and searchPagerank.c so they do not end with .c and then compile all the remaining .c files together as follows to produce an executable called scaledFootrule.
mv pagerank.c pagerank.c~
mv searchPagerank.c searchPagerank.c~
gcc -Wall -Werror -g *.c -o scaledFootrule -lm
# run tests
Every time you make a submission, a dryrun test will be run on your code to ensure that it compiles. Please ensure that your final submission successfully compiles, even for parts that you have not completed.
Assessment
This assignment will contribute 20% to your final mark.
Correctness
80% of the marks for this assignment will be based on the correctness and performance of your code, and will be mostly based on autotesting. Marks for correctness will be distributed as follows:
| Part 1 | 50% of the correctness mark |
| Part 2 | 25% of the correctness mark |
| Part 3 | 25% of the correctness mark Note: A correct brute-force algorithm is worth 65% of this. You will only receive 100% of this if you devise a "smart" algorithm that avoids checking all possible permutations. See Part 3 for details. |
Additionally, you must ensure that your code does not contain memory errors or leaks, as code that contains memory errors is unsafe and it is bad practice to leave memory leaks in your program. Submissions that contain memory errors or leaks will receive a penalty of 10% of the correctness mark. Specifically, there will be a separate memory error/leak check for each part, and the penalty will be 10% of the marks for that part. You can check for memory errors and leaks with the valgrind command:
valgrind -q --leak-check=full ./pagerank command-line-arguments... > /dev/null valgrind -q --leak-check=full ./searchPagerank command-line-arguments... > /dev/null valgrind -q --leak-check=full ./scaledFootrule command-line-arguments... > /dev/null
Programs that contain no memory errors or leaks should produce no output from these commands. You can learn more about memory errors and leaks in the Debugging with GDB and Valgrind lab exercise.
Style
20% of the marks for this assignment will come from hand marking of the readability of the code you have written. These marks will be awarded on the basis of clarity, commenting, elegance and style. The following is an indicative list of characteristics that will be assessed, though your program will be assessed wholistically so other characteristics may be assessed too (see the style guide for more details):
- Good separation of logic into files
- Consistent and sensible indentation and spacing
- Using blank lines and whitespace
- Using functions to avoid repeating code
- Decomposing code into functions and not having overly long functions
- Using comments effectively and not leaving planning or debugging comments
The course staff may vary the assessment scheme after inspecting the assignment submissions but it will remain broadly similar to the description above.
Originality of Work
This is an individual assignment. The work you submit must be your own work and only your work apart from exceptions below. Joint work is not permitted. At no point should a student read or have a copy of another student's assignment code.
You may use small amounts (< 10 lines) of general purpose code (not specific to the assignment) obtained from sites such as Stack Overflow or other publicly available resources. You should clearly attribute the source of this code in a comment with it.
You are not permitted to request help with the assignment apart from in the course forum, help sessions or from course lecturers or tutors.
Do not provide or show your assignment work to any other person ( including by posting it on the forum) apart from the teaching staff of COMP2521. When posting on the course forum, teaching staff will be able to view the assignment code you have recently submitted with give.
The work you submit must otherwise be entirely your own work. Submission of work partially or completely derived from any other person or jointly written with any other person is not permitted. The penalties for such an offence may include negative marks, automatic failure of the course and possibly other academic discipline. Assignment submissions will be examined both automatically and manually for such issues.
Relevant scholarship authorities will be informed if students holding scholarships are involved in an incident of plagiarism or other misconduct. If you knowingly provide or show your assignment work to another person for any reason, and work derived from it is submitted, then you may be penalised, even if the work was submitted without your knowledge or consent. This may apply even if your work is submitted by a third party unknown to you.